SLU Models
从研究方向来看,SLU模型分为以下几类:
- 基础的SLU模型:例如Joint Seq (Hakkani-Tur, 2016),Attention BiRNN (Liu and Lane, 2016),Slot-Gated Attention (Goo et al., 2018),CAPSULE-NLU (Zhang et al., 2019),SF-ID Network (E et al., 2019),BERT (Devlin et al., 2019)等等,这些模型属于SLU任务中最核心的基线模型,在研究类似于跨领域、跨语言迁移、zero/few-shot等特定场景下SLU任务时,一般会以这些模型作为骨干。
- 跨语言迁移SLU:Sequence Tagging with Contextual and Non-Contextual Subword Representations: A Multilingual Evaluation
- 跨领域迁移SLU:A Progressive Model to Enable Continual Learning for Semantic Slot Filling,Concept Transfer Learning for Adaptive Language Understanding
- 数据增强:Data Augmentation with Atomic Templates for Spoken Language Understanding,Data Augmentation by Data Noising for Open-vocabulary Slots in Spoken Language Understanding
- zero/few-shot:Robust Zero-Shot Cross-Domain Slot Filling with Example Values
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction
note: https://helicqin.github.io/2018/12/03/Slot-Gated%20Modeling%20for%20Joint%20Slot%20Filling%20and%20Intent%20Prediction/
NAACL 2018
本文通过提出的slot-gate建立intent到slot的联系。

Slot-Gate Mechanism


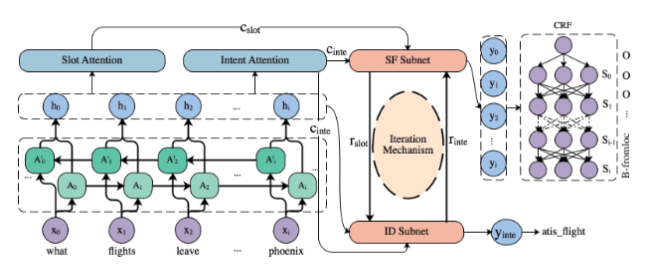
A Novel Bi-directional Interrelated Model for Joint Intent Detection and Slot Filling
目前大部分关于NLU的工作集中于将两个子任务Intent Detection和Slot Filling联合优化,早期的论文只是隐式的将损失函数相加,而Slot-gated modeling for joint slot filling and intent prediction提出了将ID的信息融合进SF的识别过程中,发现能够促进SF的效果。本文在此基础上,综合考虑了ID->SF和SF->ID两方面的影响,同时提出了一种多重交互的机制来不断增强两个任务之间的联系,在ATIS和Snips公开数据集上取得了很好的效果。
A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding
EMNLP 2019
与上两篇文章不同的是,本文直接使用indent的结果作为slot fillling的输入,而不是隐层状态,并且,作者对每一个token做意图识别,但也仅仅是单向的联系。

BERT for Joint Intent Classification and Slot Filling
使用BERT做SLU,效果比较好,方法很传统。
code: https://github.com/monologg/JointBERT, https://github.com/MahmoudWahdan/dialog-nlu

Data Augmentation by Data Noising for Open-vocabulary Slots in Spoken Language Understanding
NAACL 2019,https://drive.google.com/open?id=14gOJzuT2ORvogpveJCE7fqtTD2MzpKSQ
这篇文章主要解决的是取值空间很大的slot识别问题。例如歌名、人名之类的slot:
‘Open-vocabulary’ slots, such as the name of a restaurant or the title of a song, have no restriction on the length or the specific patterns of content in the slot.
识别这种slot更多需要上下文信息,而非slot中的单词信息。本文基于这个思想,人为给slot中的每个词加入噪声,使得模型更依赖于上下文,而非slot内部词。例如,对下图中的所有slot words的输入词向量添加一个随机噪声,而其余词不变,然后再输入到正常的模型中。此外,作者还取一个中心词的左右窗口词的词向量拼接,作为中心词的输入词向量。

Iterative Delexicalization for Improved Spoken Language Understanding
paper link: https://drive.google.com/open?id=17kYLisk6tGoWVerMyJTWvo0j7554ZANN
这篇文章主要解决的也是Open-vocabulary slots 问题,文中称之为OOD(Out of Distribution)slots:
these models often suffer from poor slot labeling accuracy when an utterance contain slots with large semantic variability, dissimilar to those encountered during training e.g. message text, partial show/artist names. In this paper, we refer such slots as out-of-distribution (OOD) slots.
与上文不同的是,本文采用的是对输入文本预处理的方法,而非基于模型的方法。具体来说,是将输入文本中的slot words用特殊的字符替换掉,这个过程叫做delexicalization,参见下图:
在SLU模型训练过程中,人为地将训练集中的数据以一定的概率p替换slot words,相当于一种数据增强的方式,然后在增强后的数据集上训练SLU模型。
而在推理(预测)时,则采用下列迭代式delexicalization算法:

上述算法中的Seed delexicalization是字符串匹配的方法,而Model based delexicalization则是根据上一轮迭代后SLU预测的结果序列来进行以下规则处理,使用每一个词预测概率分布的熵来计算分数:
A Progressive Model to Enable Continual Learning for Semantic Slot Filling
本文研究在给定新数据下的slot filling任务,在实际场景中,部署后的模型需要持续的学习新的用户表达,而直接重新训练一个新的模型往往不现实,因此,需要在已有的模型和新数据上学习一个新的模型,同时要解决灾难遗忘的问题。EMNLP 2019
Learning Out-of-Vocabulary Words in Intelligent Personal Agents
IJCAI 2018, https://drive.google.com/open?id=1kBfUk3p88gx9gJMiqiD7jIysJ9plmiED
这篇文章在传统的semantic parsing的基础上增加了一个句子改写的任务,来提高OOV词汇的识别能力。
Data Augmentation with Atomic Templates for Spoken Language Understanding
EMNLP 2019, https://drive.google.com/open?id=1slDC8H0jPDFcQ6XZozOR4DZsXejn_8sm
本文研究SLU任务的数据增强问题,通过给定dialog act对应的atomic template,然后根据一个seq2seq的生成模型来生成dialog act对应的自然语言描述。
这里的SLU模型是hierarchical decoding(HD)的方法,与传统的槽填充+意图识别不同:
Concept Transfer Learning for Adaptive Language Understanding
SIGDial 2018: https://drive.google.com/open?id=18cnjAWlc-jPfSB9HQs1RxmJfco0EfLnB
本文将slot filling任务中的slot拆分成更小的原子单元:
然后通过这些层级关系来共享一部分的atomic concepts,以达到迁移的目的,尤其是迁移到新领域、新的slot type。下图是模型结构:
作者把预测BIO标签和每个atomic branch上的每个单元作为多个任务,共享一部分底层参数,然后再把所有预测的结果拼接起来组合成最终的slot type。作者还提出了一种利用slot name作为描述信息的分类模型,用slot name得到每个type的向量表示,作为softmax的W参数。
Robust Zero-Shot Cross-Domain Slot Filling with Example Values
ACL 2019, https://drive.google.com/open?id=1jX18H04WidyW51ncEr-NXhtkbmDa3HgC
本文研究利用slot描述(本文直接使用slot name)和少量的slot value来做zero-shot的跨领域迁移。

Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference
- date: 2019/11/28
- tags: Spoken Language Understanding
- summary: 本文研究的是结合对话上下文的自然语言理解系统,一般的SLU只处理单个句子,而本文则是希望利用整个context信息来辅助理解。论文的创新点在于在SLU任务的基础上联合了句子顺序预测的任务,通过多任务学习来更好的理解context。
- conference: ACL 2019

从上图可以看出,在不考虑对话上下文的前提下,是没法预测“6“这个token的。

模型本质上是一个memory network,重点关注DLI模块:在给定前k个utterance的基础上,DLI从(k+1,n)中预测下一个utterance,这里构建多个二分类:
因此,DLI的损失函数定义为:
整体的损失为:
PAWS: Paraphrase Adversaries from Word Scrambling
词序和语法结构对句意有很大影响,换而言之细微的词序调整也可能会完全改变句意。请思考以下例句:
Flights from New York to Florida. 从纽约飞往佛罗里达的航班。
Flights to Florida from New York. 从纽约飞往佛罗里达的航班。
Flights from Florida to New York. 从佛罗里达飞往纽约的航班。
三个句子均使用完全相同的单词。但第 1 句和第 2 句意思相同,称为 _释义对_ (Paraphrase Pairs);而第 1 句和第 3 句的意思截然不同,称为 _非释义对_ (Non-Paraphrase Pairs)。识别对应语句对是否为释义对的任务称为_释义识别_ (Paraphrase Identification),对自然语言理解 (Natural Language Understanding, NLU) 的实际应用(如问答系统)至关重要。
可能有些出乎意料,但如果仅在现有的数据集上训练,即使是 BERT 等最高水准 (SOTA) 模型也无法正确识别许多非释义对之间的差异(如上文中的第 1 句和第 3 句)。这是由于现有的数据集缺乏针对这种情况的训练数据。因此,即使能够理解复杂的上下文句式的机器学习模型,也很难理解此类任务。
为解决这一问题,本文发布两个新数据集以帮助社区进行相关研究:
PAWS (Paraphrase Adversaries from Word Scrambling) 英文数据集;
PAWS-X 数据集,基于 PAWS 数据集并扩展为六种不同语言:法语、西班牙语、德语、中文、日语和朝鲜语。
两个数据集均包含结构完整、单词重叠度较高的句对,其中约有一半是释义对,而另一半是非释义对。通过在 SOTA 模型的训练数据中加入新数据,我们将算法的精确度从低于 50% 提升至 85-90%。与之前相比,即便使用新的训练示例,无法获得非本地上下文信息的模型同样会训练失败。因此,新数据集也成为了测量模型对词序和单词结构敏感度的实用工具。
PAWS 数据集包含 108,463 个由人工标记的英文句对,这些数据来源于 Quora Question Pairs (QQP) 和维基百科。PAWS-X 包含 23,659 个由人工翻译的 PAWS 评估句对 (Evaluation Pairs) 和 296,406 个机器翻译的训练句对。下表列出了两个数据集的详细统计数据。

Improving Slot Filling by Utilizing Contextual Information
arXiv 2019.11, https://arxiv.org/pdf/1911.01680.pdf
论文出发点是增强上下文理解能力来识别一个词,新建了两个额外的辅助任务:
- In the first auxiliary task we aim to increase consistency between the word representation and its context.
- The second auxiliary task is to enhance task specific information in contextual information.
对于slot filling主任务,作者使用预训练BERT作为词编码,然后通过一个BiLSTM得到每个词的表征$h_{i}$。作者还使用额外的句法解析的结果作为输入,然后以$h_{i}$作为每个节点(即每个词)的初始表示,通过GCN多层传播,最终把BiLSTM的输出与GCN的输出拼接,得到每个词的表示 $h_{i}^{\prime}=C O N C A T\left(h_{i}, \hat{h}_{i}\right)$。最后再通过FC和CRF层预测输出BIO标签。
对于第一个任务,作者首先计算第i个词对应的上下文表征$h_{i}^{c}=M a x P o o l i n g\left(h_{1}, h_{2}, \dots, h_{N} / h_{i}\right)$ (实际取这个序列中除$h_{i}$以外的所有词表征做池化),作者想增加$h_{i}$与$h_{i}^{c}$之间的一致性,因此增加了一个mutual information (MI)损失:
$$
M I\left(X_{1}, X_{2}\right)=D_{K L}\left(P_{X_{1} X_{2}} | P_{X_{1}} \otimes X_{2}\right)
$$
实际使用的是一种近似方法mutual information neural estimation (MINE):
(这里的$h$应该是$h_{i}$),上式很好理解,正样本$h_{i}, h_{i}^{c}$的相关性要大于负样本$h_{i}, h_{j}^{c}(j\neq i)$,D是一个判别器。
对于第二个任务,作者又设计了两个子任务:
The first one aims to use the context of each word to predict the label of that word and the goal of the second auxiliary task is to use the global context information to predict sentence level labels.
- Predicting Word Label: $P_{i}\left(\cdot |\left\{x_{1}, x_{2}, \ldots, x_{n}\right\} / x_{i}\right)=
\operatorname{softmax}\left(W_{2} \ast \left(W_{1} \ast h_{i}^{c}\right)\right)$ - Predicting Sentence Labels:
$$H=\operatorname{MaxPooling}\left(h_{1}, h_{2}, \ldots, h_{N}\right) \\ P\left(. | x_{1}, x_{2}, \ldots, x_{N}\right)=\sigma\left(W_{2} \ast \left(W_{1} \ast H\right)\right)$$
实验做的很糟糕。